☢ Usage ☢
☆ Working in UTAU ☆
Lyrics
For the most part, lyric insertion is a manual process, however there are some tools you can use to make it a little easier. First, let's go over how it works manually.
If we have these lyrics: <twinkle twinkle little star / how I wonder what you are>, we first need to break them down into their phonetic components, something like:
t w I N . k @l . t w I N . k @l . l I . 4 @l . s t A r
h aU . aI . w V n . d @r . w V . tS u . A r
It's important to think of each phone in a phrase context rather than in an isolated word or syllable. <what you> could be transcribed as w V t . j u, but this might not sound as natural within the rest of the phrase.
Phonetic transcription is a skill, though, so just try your best to sound out the phrase rather than thinking of each word separately or relying on spelling. You may try out several phonemes within a given voicebank until you find one that sounds best to you.
Next, we apply these to the UST, using the appropriate samples to transition from one phone into the next:
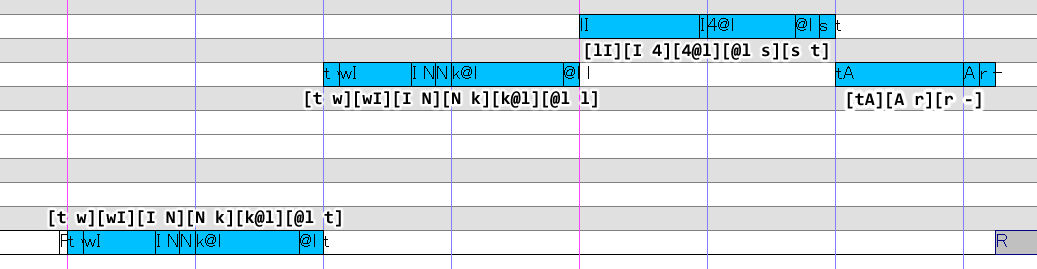

The primary type of note that will be used is medial CV, secondarily transitional VC. Also, while there are no initial plosives, we can use a short rest to mitigate any noise.
For a voicebank with additional samples, we may use something like this instead:
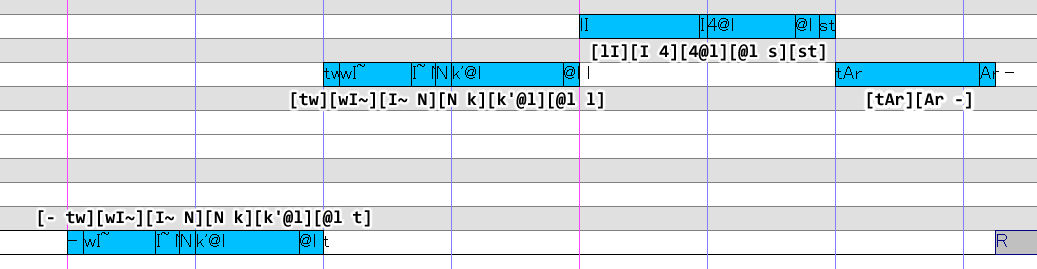
This image was using a slightly older version of the reclist; aspirated plosives are now transcribed with [h] instead of ['].
The specific samples and arrangement chosen is going to depend a lot on the song and the voicebank. The important thing is to think about the transitions from sample to sample, and how you can work with those in voicebank to achieve the desired phonetic output.
For example, here are two additional ways we could represent the word <are>:
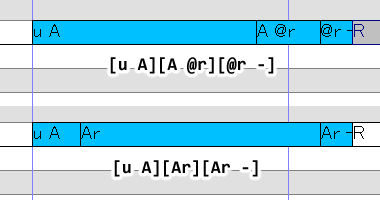
In the first, we use [@r] in place of [r] for a longer coda. In the second, we blend the [u A] sample with the sustained [Ar] to get a more natural sounding rhotic.
Timing
In most cases, the nucleus should line up with the start of the music note. This means that whatever note is hitting in time is most often going to be a CV; the preutterance already bumps the CV's consonant before the beat, but any other consonants being blended with the CV should also go before the start of the music note.
There are a few exceptions, however; C + approximant onset clusters sometimes see the approximant hitting on the beat, such as the [tw] shown above.
When timing consonants, keep in mind that most consonants will have a length of about 50~100 msec, which means the length of a sample ending in a consonant will usually be shorter than a 16th note. You can actually see the precise duration in the bottom left corner:
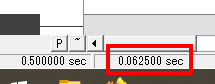
At 0.0625 seconds, this means this sample is rendered for 62.5 msec. Sibilants like [s, z, S, Z, tS, dZ] tend to have slightly longer durations, sitting around 75~125 msec. Taps/flaps like [4] will have much shorter durations at around 15~45msec and rarely need to be longer than a 64th note.
The length of the consonant is not impacted by tempo in the sense that faster tempo = shorter consonant, but it is impacted in the sense than shorter overall note duration = shorter consonant. So, a note preceeded by a 16th note may have a shorter onset than a note preceeded by a half note, because there is less space in the utterance for the consonant to exist in. Phonemes of all sorts are also frequently reduced, assimilated, or deleted in fast environments; your mouth muscles can only move so fast.
Slow tempos and/or long notes usually provide enough room for the consonant to play out at maxmimum duration, but they don't really scale. A consonant that's uttered at 75msec at 180 BPM note is probably going to stay 75msec at 80 BPM, and if it does get longer it won't be by much.
Plugins: Presamp & autoCVVC
To make lyric insertion a little easier, you can use a combination of presamp and autoCVVC 2.0, both developed by Delta. For English instructions on how to install and set up presamp, as well as an English translation of the interface, see here.
To use presamp with a given S-CVVC voicebank, make sure it has a presamp.ini in the voicebank's root folder. To add a presamp.ini to your own S-CVVC voicebank, you can use one of the presamp templates I've created and, if necessary, edit it to suit any custom samples you've included.
Next, in the project settings for the UST, make sure that both resampler and wavtool are set to presamp.exe, with the file path being wherever you saved presamp to. Run the predit plugin (included with presamp) to set the resampler and wavtool you want to render with.
Now, you can type in whole syllables into the lyric rather than having to manually split off VCs and CCs, like so:

NOTE: Presamp does not have a dictionary; you will still need to write the syllables phonetically.
When you render it, it should parse most if not all of the transitional samples automatically. If it doesn't work correctly, try running predit again or resetting the note crossfade to force a new render.
This can sound passable on it's own, but more than likely you'll want to do some manual edits. To do that, run autoCVVC 2.0 with presamp enabled. This will split up the notes for you based on your autoCVVC settings and the presamp.ini specifications, and allow you to edit them for more precise lyrics.

After doing this, you don't need to render with presamp anymore, so you can change the UST's resampler and wavtool to whatever you want.
Known Presamp Limitations
- Diphthongs and R/L vowels do not always work correctly. For example, it will use [V V] instead of [V] on diphthongs.
- CCs aren't always parsed correctly, and timings may be weird. You may need to play around with how you write the syllables to get it to render right.
- It will not use initial consonants, onset CCs, or 3+ coda CCs.
- It will not use glottal stop VCs.
Other Settings
It's generally a good idea to set the modulation of all notes to 0, or at least to a very low number, to stablize the pitch of the sample transitions.
Additionally, you'll want to crossfade them, but shouldn't need to manually adjust the envelopes in most cases.
And, lastly, if any of your consonant samples get too loud or hissy-sounding, I recomend decreasing their intensity. This happens sometimes with voiceless consonants.
☆ Working in OpenUTAU ☆
Working in OpenUTAU is much easier in a lot of ways, with the main drawback being that OU is still in active development.
S-CVVC is compatible with the English X-SAMPA Phonemizer (formerly called the Delta phonemizer).
This means that, for the most part, you can type in English words and it will parse the phonemes from the built in dictionary. Multisyllable words can be split across notes using [+].
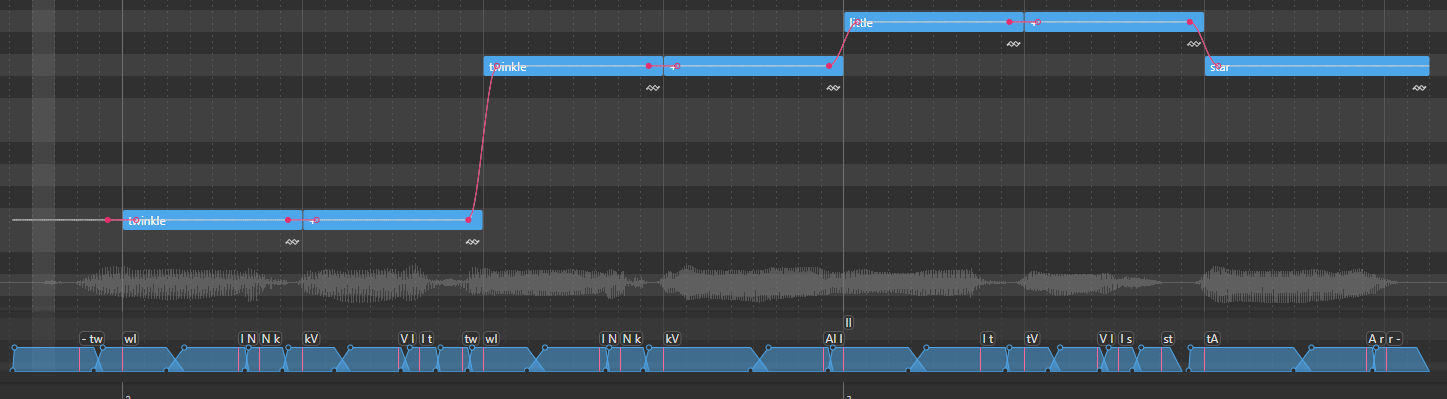
The phonemizer has some limitations, namely that it won't use every phone that the voicebank includes by default, so the pronunciation can be a bit stiff. However, you can tell it what specific phones to use for a word by enclosing them in brackets within the lyric box:
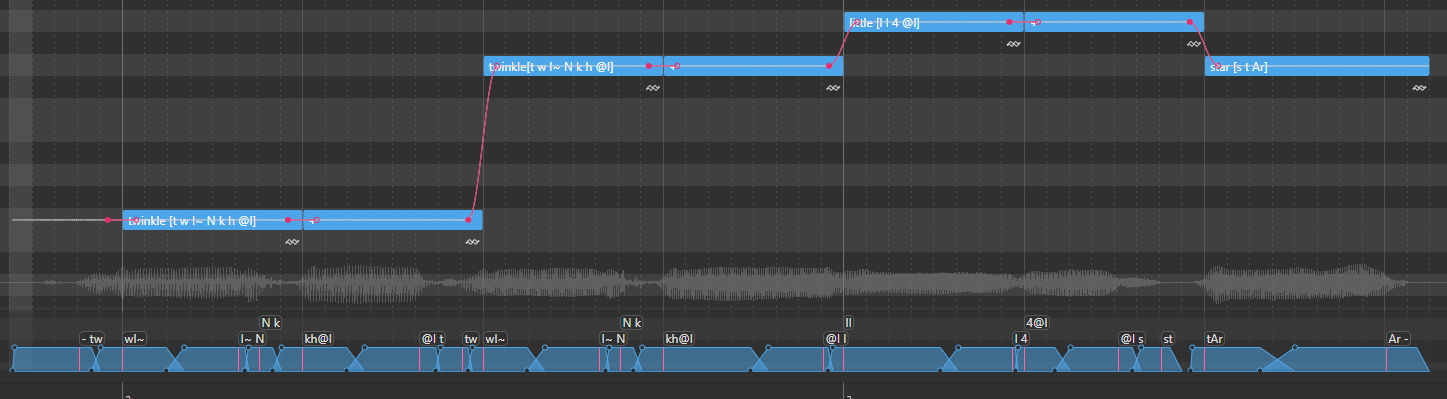
TIP: You can get it to use aspirated plosives by treating them like consonant clusters, e.g. cat[k h { t].
You can also adjust the timing and aliases of individual samples by editing the envelopes at the bottom of the window.